LightGBM LambdaRank 参数优化指南
LambdaRank 是 LightGBM 中用于排序任务(Learning to Rank) 的目标函数,特别适合解决搜索引擎、推荐系统等场景中的排序问题。
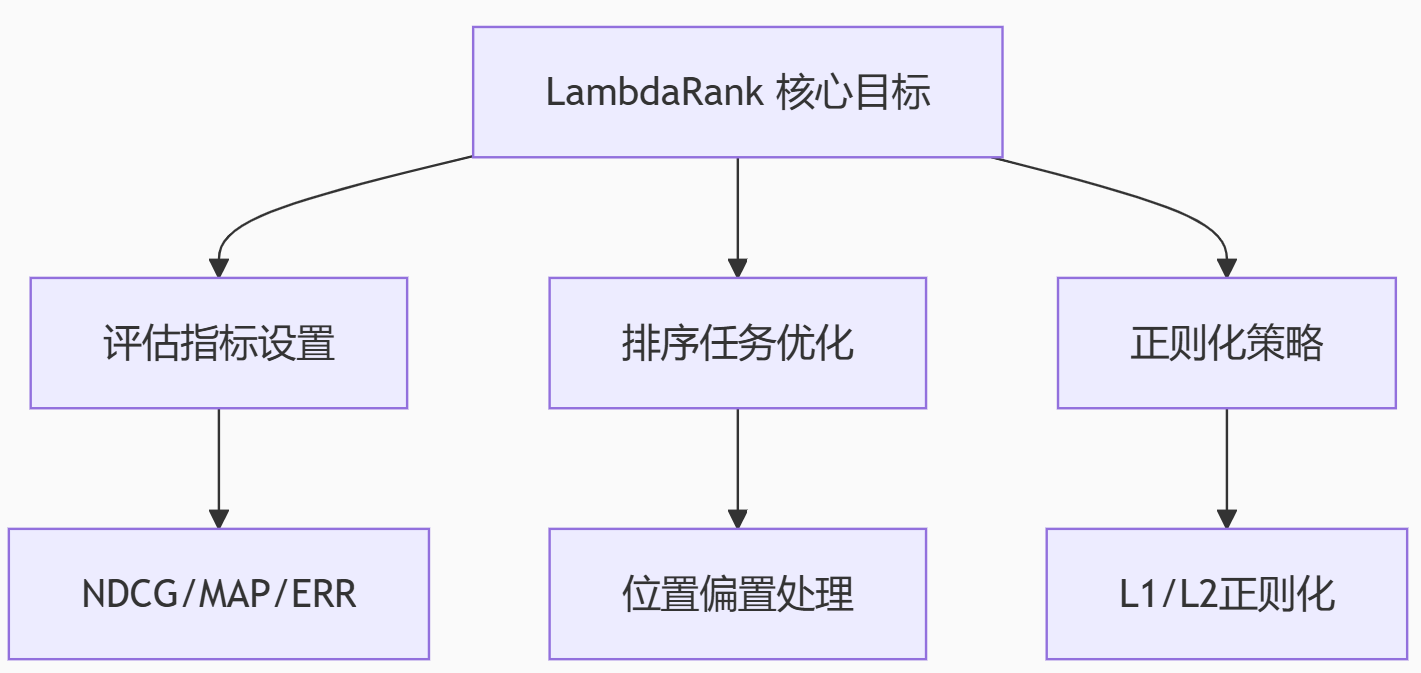
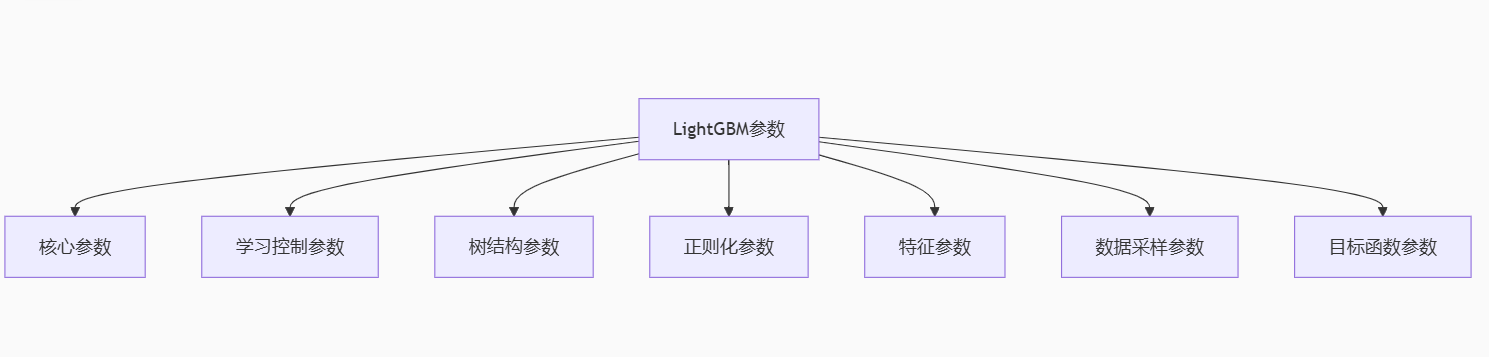
一、LambdaRank 专属参数
| 参数 | 推荐值 | 说明 | 重要性 |
|---|
objective | lambdarank | 必须设置为 lambdarank | ★★★★★ |
metric | ndcg | 评估指标 (也可选 map, err) | ★★★★★ |
ndcg_eval_at | [5, 10] | 计算 NDCG@5 和 NDCG@10 | ★★★★☆ |
lambdarank_truncation_level | 10 | 计算增益时的截断位置 | ★★★★☆ |
lambdarank_norm | true | 是否归一化 NDCG | ★★★☆☆ |
lambdarank_position_bias_regularization | 0.5-1.0 | 位置偏置正则化强度 | ★★★★☆ |
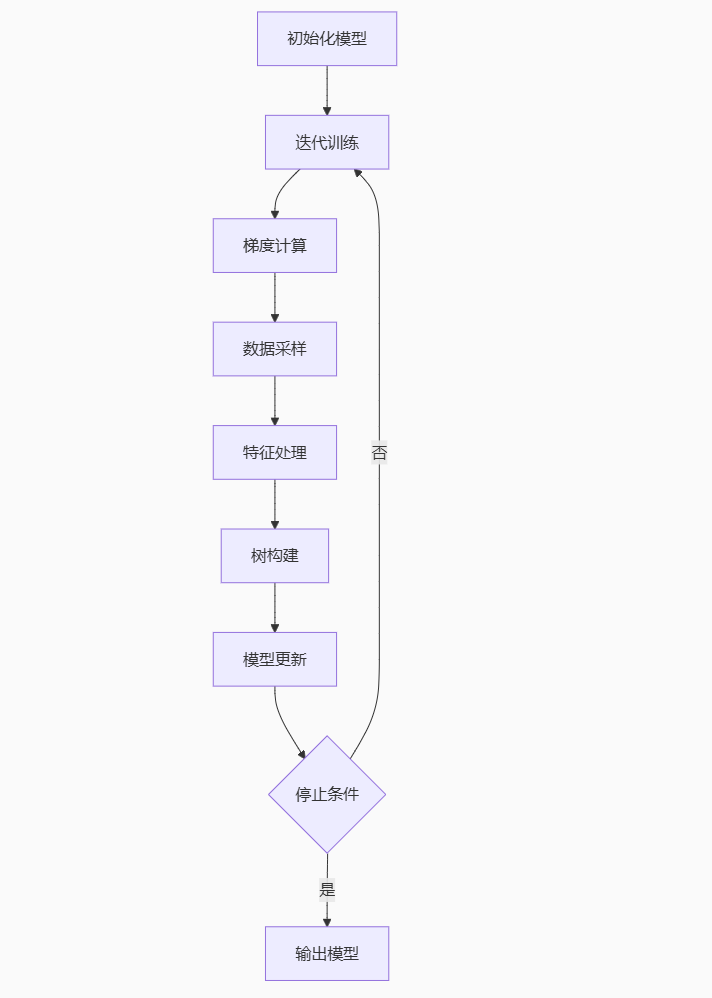
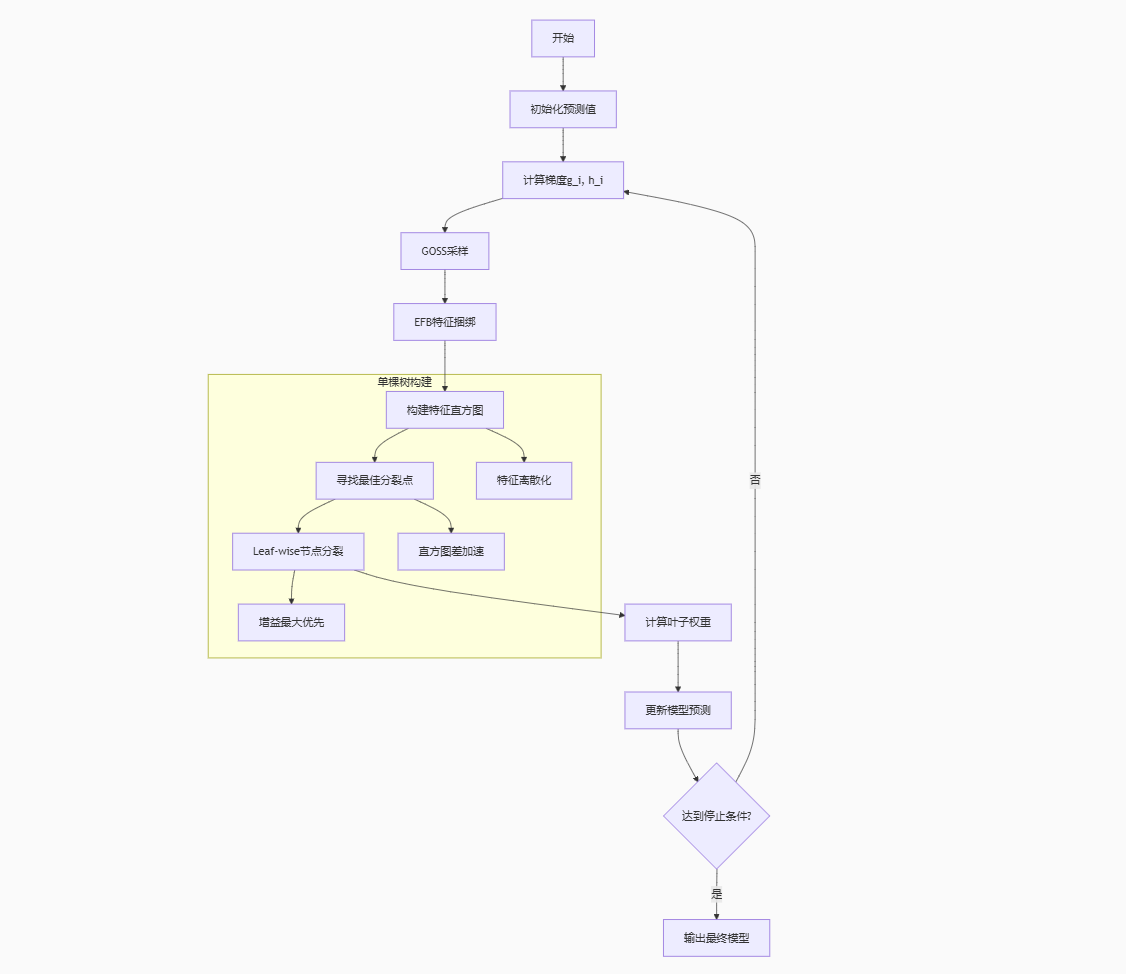
二、基础参数优化组合
base_params = {
# 核心目标
'objective': 'lambdarank',
'metric': 'ndcg',
'ndcg_eval_at': [5, 10],
# LambdaRank 专属
'lambdarank_truncation_level': 10,
'lambdarank_norm': True,
'lambdarank_position_bias_regularization': 0.8,
# 学习过程
'learning_rate': 0.05,
'num_iterations': 2000,
'early_stopping_rounds': 50,
# 树结构
'num_leaves': 127,
'max_depth': 8,
'min_data_in_leaf': 100,
# 正则化
'lambda_l1': 0.2,
'lambda_l2': 0.3,
'min_gain_to_split': 0.1,
# 特征处理
'feature_fraction': 0.8,
'max_bin': 255,
# 硬件加速
'device': 'gpu',
'gpu_platform_id': 0,
'gpu_device_id': 0
}
1. 大规模数据集优化
large_data_params = {
**base_params,
'learning_rate': 0.02,
'num_iterations': 5000,
'min_data_in_leaf': 500,
'max_bin': 511,
'feature_fraction': 0.7,
'extra_trees': True # 增加随机性
}
3. 多目标排序
multi_metric_params = {
**base_params,
'metric': ['ndcg', 'map'],
'eval_at': [3, 5, 10],
'lambdarank_weight': [0.7, 0.3] # NDCG和MAP的权重
}
高位置偏置场景
position_bias_params = {
**base_params,
'lambdarank_position_bias_regularization': 1.5,
'lambdarank_truncation_level': 20,
'max_position': 50, # 定义最大位置
'label_gain': [0,1,3,7,15,31,63] # 自定义标签增益
}