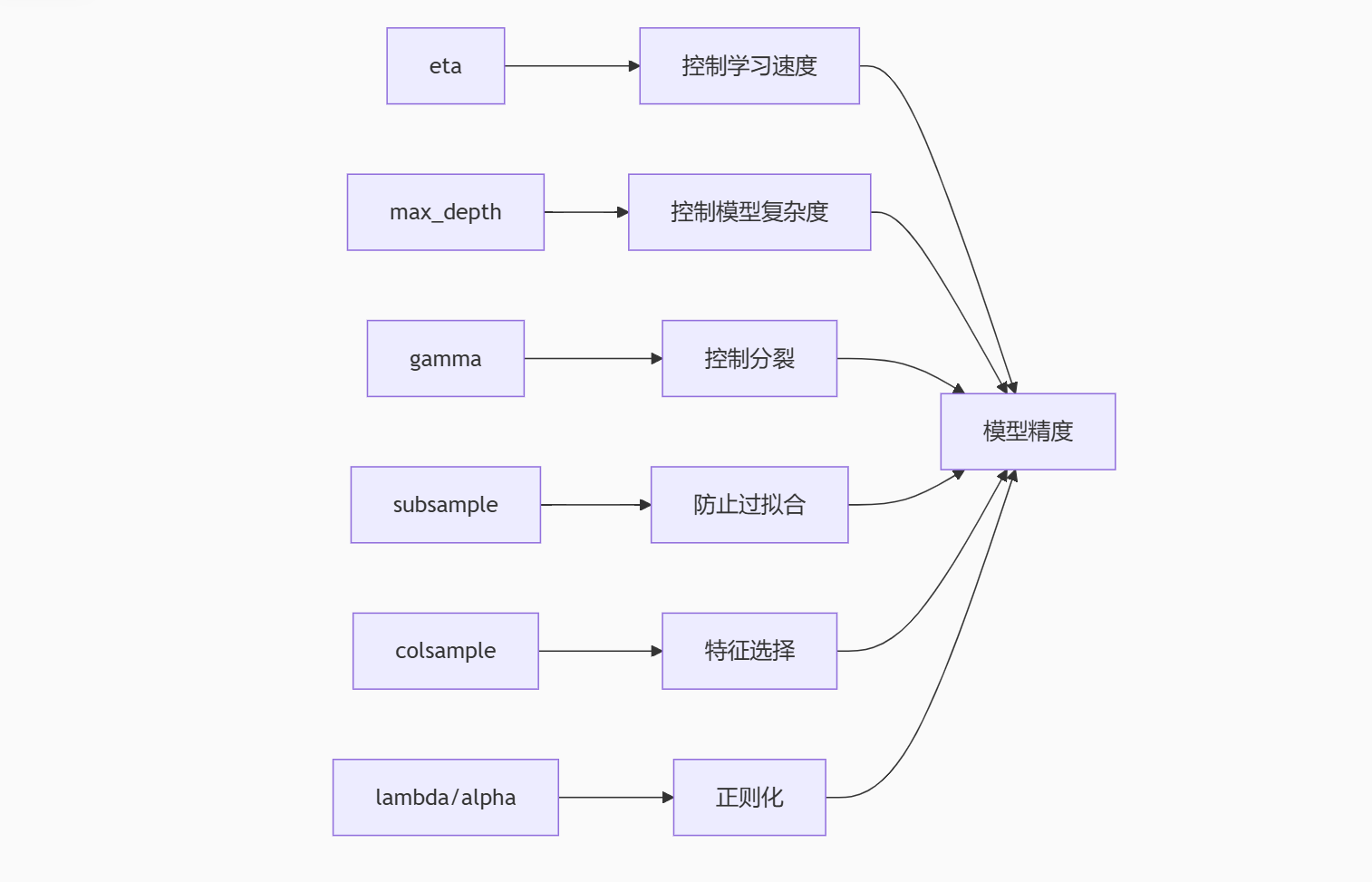
2. 参数优化阶段
2.1 调整树结构参数
# 网格搜索树结构参数
param_grid = {
'max_depth': [3, 5, 7],
'min_child_weight': [1, 3, 5],
'gamma': [0, 0.1, 0.2]
}
best_score = 0
best_params = {}
for depth in param_grid['max_depth']:
for weight in param_grid['min_child_weight']:
for gamma in param_grid['gamma']:
params = {
'max_depth': depth,
'min_child_weight': weight,
'gamma': gamma,
'objective': 'binary:logistic',
'eval_metric': 'logloss'
}
# 交叉验证
cv_results = xgb.cv(
params, dtrain,
num_boost_round=100,
nfold=5,
metrics={'logloss'},
early_stopping_rounds=10,
seed=42
)
# 选择最佳参数
min_logloss = cv_results['test-logloss-mean'].min()
if min_logloss < best_score or best_score == 0:
best_score = min_logloss
best_params = params.copy()
print(f"最佳树结构参数: {best_params}")
2.2 优化正则化参数
# 优化正则化参数
param_grid = {
'reg_alpha': [0, 0.1, 0.5, 1],
'reg_lambda': [0.5, 1, 1.5, 2]
}
for alpha in param_grid['reg_alpha']:
for lambda_val in param_grid['reg_lambda']:
params = best_params.copy()
params.update({
'reg_alpha': alpha,
'reg_lambda': lambda_val
})
# 交叉验证
cv_results = xgb.cv(
params, dtrain,
num_boost_round=100,
nfold=5,
metrics={'logloss'},
early_stopping_rounds=10,
seed=42
)
# 更新最佳参数
min_logloss = cv_results['test-logloss-mean'].min()
if min_logloss < best_score:
best_score = min_logloss
best_params = params.copy()
print(f"优化后参数: {best_params}")
2.3 调整学习率和树的数量
# 调整学习率和树的数量
learning_rates = [0.01, 0.05, 0.1]
best_num_rounds = 0
best_lr = 0
for lr in learning_rates:
params = best_params.copy()
params['learning_rate'] = lr
# 使用早停确定最佳树的数量
evals_result = {}
model = xgb.train(
params, dtrain,
num_boost_round=1000,
evals=[(dtrain, 'train'), (dtest, 'eval')],
early_stopping_rounds=20,
evals_result=evals_result,
verbose_eval=False
)
# 记录最佳迭代次数
best_iteration = model.best_iteration
best_score = model.best_score
if best_score < best_score or best_score == 0:
best_num_rounds = best_iteration
best_lr = lr
best_params['learning_rate'] = best_lr
print(f"最佳学习率: {best_lr}, 最佳树数量: {best_num_rounds}")